



生成AI時代に求められる“AIのためのデータマネジメント”をAIエージェントで実現する
写真左から
技術本部システム研究開発センター 森 崇晃さん、光野 泰弘さん、大江 賢さん
データは蓄積されているのに、十分に活かしきれない――。多くの企業が直面するこの課題の本質は、データ分析の手前にある「整備」や「判断」に、いまだ膨大な人手と時間がかかっている点にあります。
メタデータの整理、利用ルールの確認、ルールに準じたデータ加工などの作業はデータ活用を支える重要な業務です。これらの作業をAIエージェントが担い、データ活用に適した状態へと自律的に整える。そうした仕組みこそがデータ活用を加速させる鍵となります。
さらに生成AI時代には、人のためだけでなく、AIの能力を十分に発揮できるようデータそのものやメタデータ、コンテキストを整備する「AIのためのデータマネジメント」が求められています。その実現を担うのもデータマネジメントを支援・代替するAIエージェントです。
本記事では、生成AI/AIエージェントを活用したデータマネジメントの最前線をご紹介します。
データ基盤や関連ツールの導入はゴールではなくスタート
――まずは、シス研が取り組んできたデータマネジメントの研究についてお聞かせください。
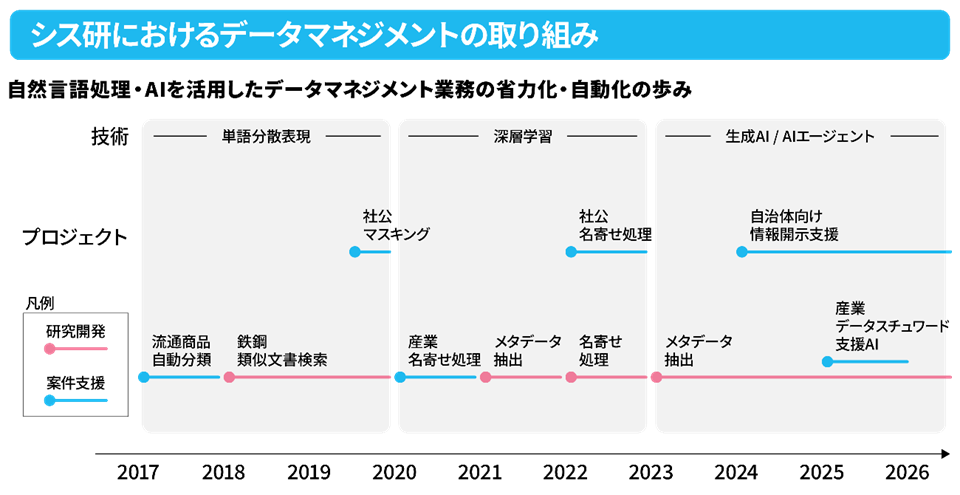
光野:私が配属直後に対応した案件では、ある小売企業様が商品データをうまく活用できないという課題を抱えていました。商品名や説明文は大量に登録されているものの、カテゴリ付与が人手に依存しており、基準も担当者ごとに揺れていました。その結果、検索や分析の精度が上がらず、業務効率にも影響が出ていました。
そこで私たちは、自然言語処理を活用して商品に自動でカテゴリを付与する仕組みを開発しました。これにより、業務の省力化だけでなく、分類基準を一定に保つことでデータの一貫性と品質を担保することができました。
これは一つの例に過ぎませんが、多くの企業で共通して見られる課題です。データは蓄積されているものの、「意味が揃っていない」「品質が一定でない」「どこに何があるか分からない」といった状態では、十分に活用することができません。私たちが取り組んでいるデータマネジメントとは、データを単に集めることではなく、意味を整理し、品質を担保し、安心して活用できる状態をつくる取り組み全般を指します。
その後も、自然言語処理技術の発展とともに、機械学習、深層学習、そして現在は生成AIを活用しデータマネジメントを省力化・自動化する研究に取り組んでいます。
――データマネジメントは関連領域も提供されているサービスも、さまざまあるかと思います。NSSOL、シス研ならではの取り組みや特徴を教えてください。
光野:おっしゃるように、データマネジメントは領域も幅広いですし、定義も企業ごとで異なったり、それぞれの深度も異なっていたりします。そのような状況を踏まえ、データマネジメント全般のコンサルティングに関する研究や、実際のサービス提供も行っています。
――単なるツールや基盤の導入だけでなく、インテグレーションやコンサルティングサービスに関する研究も行っていると。

光野:はい。具体的には、さまざまあるデータマネジメントの要素の中で、ご依頼いただいたお客さまはどの領域が不十分なのかを整理することから始まります。課題感がすでに見えている場合には、その領域に特化したコンサルティングならびに先述したような実務的なサービスを事業部のメンバーと一緒になって取り組んでいます。データマネジメントでお困りのことがあれば、どんなことでも対応するスタンスです。
データ基盤も含めた各種ツールの提供や構築に加え、データセキュリティなど専門領域を研究するチームもありますから、それらのチームとも協力しながら、お客さまをサポートする体制が整っています。
――研究を進める上で感じた、データマネジメントの課題についても教えてください。
光野:データが重要な経営資源であることには多くの企業が気づいています。特に大企業の場合は、データ基盤はもちろん、データカタログやデータマネジメントの整備が推進されているケースが大半です。
ですが、実際に現場を拝見させていただくと、ツールや体勢は整えたけれど欲しいデータが見つからない、費用対効果が不明瞭といった課題を抱えているケースが少なくありません。これらの整備はあくまでデータマネジメントのゴールではなく入り口だと捉えることが重要だと考えています。
――だからこそ、ますますデータマネジメントを推進することに意味があると。
光野:データマネジメントを推進するうえで重要なポイントは、データマネジメント施策を継続的かつ効率的に実行できる仕組みをつくることだと考えています。
例えば、社内にどういったデータがあり、そのデータを扱うために必要な情報(メタデータ)を整備することは重要です。しかし、実際の現場では整備作業が膨大で人手ではなかなか手が回らないという課題があり、その結果として「重要だと分かっているが進まない」という状態に陥っています。
そのような状態にならないために、データマネジメント施策で発生する実作業を人手だけで実行するのではなく、生成AIやAIエージェントなどの技術を用いることで効率化・自動化することに取り組んでいます。
メタデータ管理(データカタログの整備)にAIを活用して効率化
――データマネジメントにおいては作業の効率化・自動化が重要だということですね。

森:メタデータとは、データ活用に際し、該当するデータの理解を助けるデータです。具体的にはテーブルなどの物理名、論理名、各カラム、テーブル全体の説明といったデータであり、対象のデータがどういった業務で発生し、どう加工されているか、また業界特有の用語の意味もメタデータになります。そのほか、利用範囲などを定めた機微度など、得ようと思えばある意味いくらでも広がるデータですから、まずはメタデータの範囲を定めることが重要になってきます。
ただ、この業務ではデータを生み出している現場側と、実際にデータを活用したいと考えている事業部サイドでの認識が異なっているケースが少なくありません。また、メタデータを収めておくデータカタログの管理でも、同様のことが言えます。そのためメタデータの整備や管理は、かなり難しい取り組みだと言えるでしょう。
そのため私たちが同業務をコンサルティングする際には、企業規模やデータの量にもよりますが、半年ほどかかる場合はざらです。そこで私たちは同業務にAIを活用し効率化に向けた研究に取り組んでいる、というわけです。
――なるほど。おっしゃるようにメタデータはかなり幅広いですから、AIに任せた方が業務効率化できそうですね。現在はどのあたりまで研究が進んでいるのですか。
光野:基礎的な研究段階はすでに終え、現在はあるメーカーさんの何千テーブル、何万カラムという規模かつ、グループの関連会社や部門ごとに点在もしている大量のデータを整理し、最終的にはデータカタログとしてまとめ、さまざまな部門のデータ活用に寄与する。このような目的実現に向けて、実適用のフェーズに入っています。
また、単にデータカタログに登録するメタデータをAIに作成させるだけでなく、そのメタデータの品質(記述項目の充足率や読みやすさなど)を改善する仕組みも構築したことで、実業務で十分に利用できるものとなってきています。
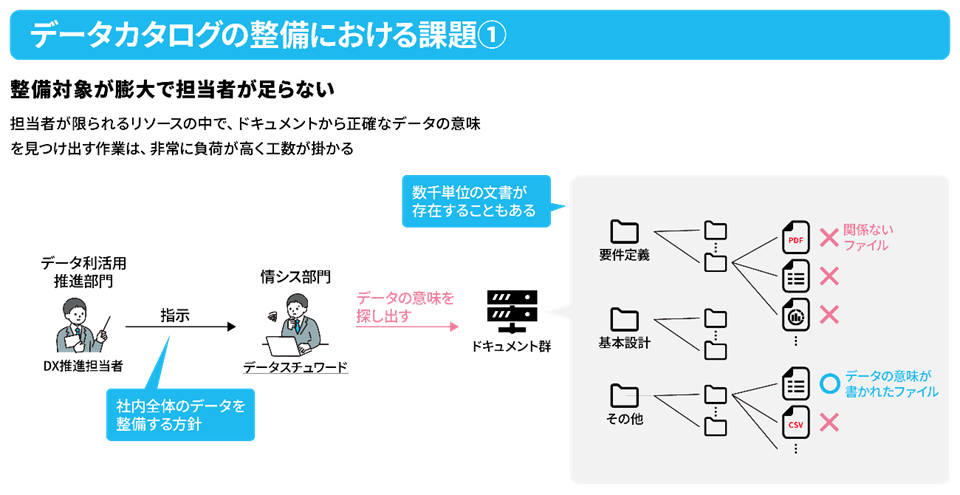
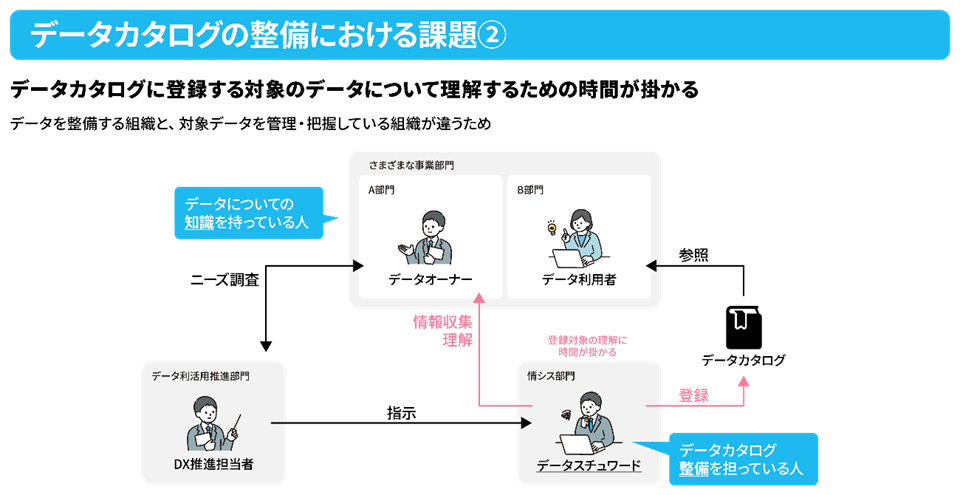
光野:こちらのお客様はこれまでも、データスチュワードがこの業務に取り組んでいました。ですが、対象データが膨大であったことやデータスチュワードが扱うデータに関する業務知識を持ち合わせていないなどの理由から、業務スピードが鈍化しているとの課題もありました。
――そのような人が行うには非効率な業務を、AIが代替すると。
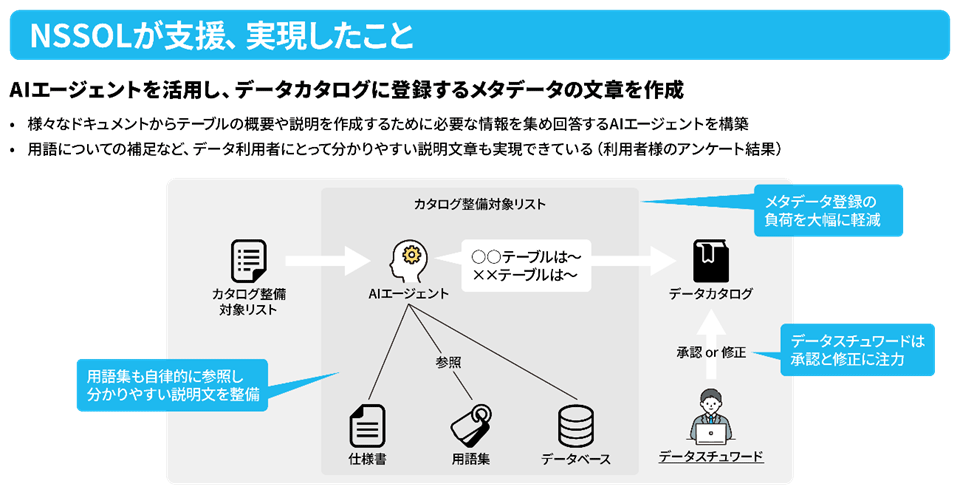
森:ええ。1年かけてPoCを行った結果、すでに数百テーブルのメタデータ、それに伴うデータカタログが併せて作成されているという成果が生まれています。
――研究やプロジェクトを進めていく上での課題や苦労はどのあたりでしたか。
森:データのフォーマットがExcel(Microsoft Excel)であったりHTMLであったりと多様であったこと。欲しいと思ったデータがどこにあるのかが分からない。AIの出力が毎回異なるなどの課題がありました。
――それらの課題を、どのように解決していったのでしょう。
森:情報検索においては、データベースならびに検索システムを構築することで対応しました。AIによる品質の不安定さにおいては、メタデータの定義をしっかりとかためておくこと、またAIエージェントを活用し、作成したメタデータの品質を改善するようなサイクルを回していくことで、作成されるメタデータの記述の正確性と品質を高めることができました。
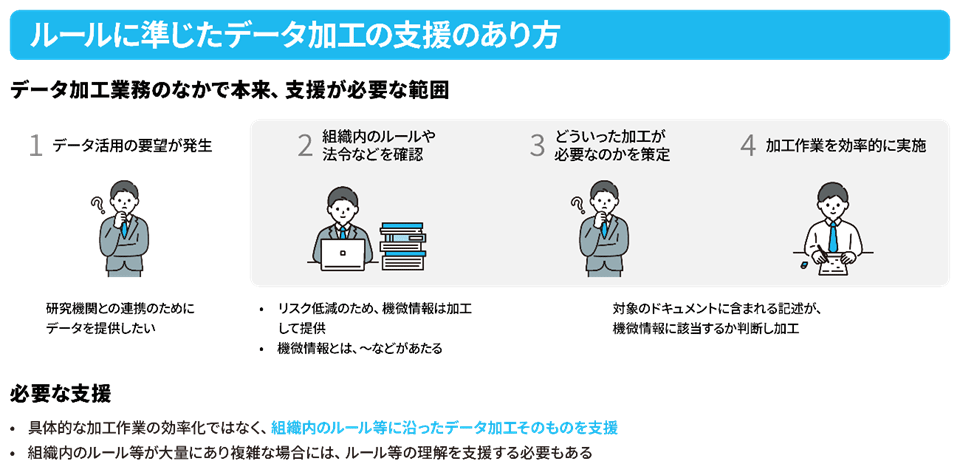
組織内のルールに準じたデータ加工を、AIで半自動化し判断作業を省力化
――その他の取り組みとしてデータ加工支援の取り組みについても教えてください。
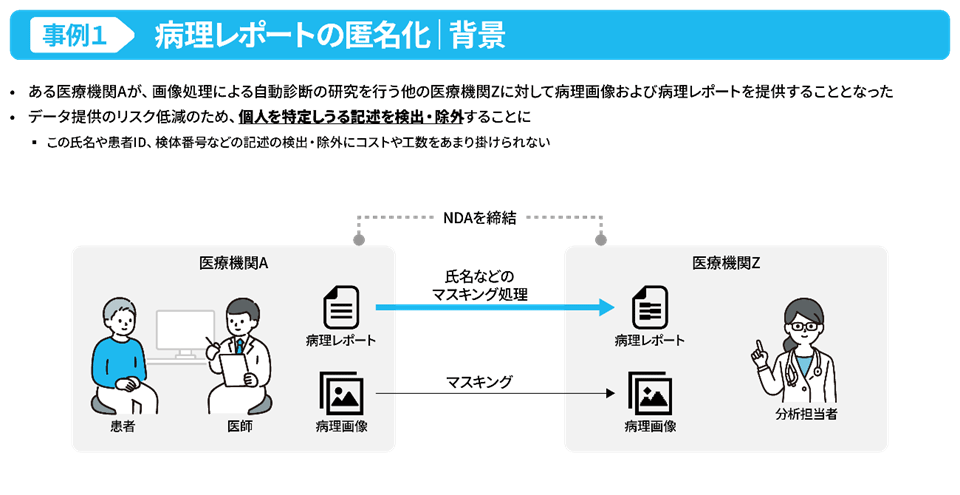
光野:この取り組みは安全にデータを使うために必要なデータ加工を支援するというものです。ある医療機関が別の医療機関に情報を提供する際に、マスキングを行う必要がありました。人が行うには工数をかなり要するため、機械学習を使って自動化を進めていきました。
この事例で我々が取り組んだ業務はマスキング業務の効率化でありましたが、組織間のデータ提供を支援するという文脈においては、スライドで示す上流の業務も含めてのデータ加工支援に取り組む必要があると考えていました。医療機関のプロジェクトであれば、マスキングするべきなのはどの要素なのか。その判断理由やマスキング方法なども、我々の研究成果を活用すれば省力化できると考えたからです。
大江:そうして取り組んだのが生成AIなどを活用し、地方自治体の情報開示請求対応業務を自動・省力化することです。自治体では、市民から情報の開示請求があった際、応じることが法令で定められていますが、個人名などはマスキングすることが同じく定められています。
そのため、担当する職員はまずは開示要求のあった情報を探す。次に、開示してはならない箇所をマスキングする。さらには、マスキングが不当であったと市民から意見を受けた際に再考し、理由も含めて再び開示する。このような業務を行っています。
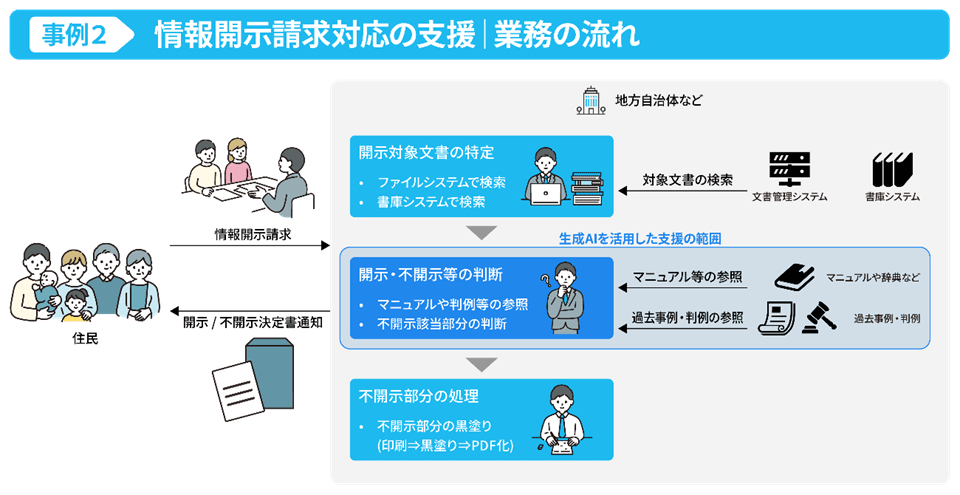
――聞いているだけで、かなりの労力を要する業務だと感じました。

大江:ええ、だからこそAIが貢献するのです。担当者は欲しい情報を入力すれば、生成AIが情報の検索はもちろん、どのような条例を参考にマスキングを行ったのか、審査会で覆った場合には、その理由も含めて過去の答申の内容を参照し、提示してくれます。参照先のドキュメントは10数ページのボリュームになることもありますから、具体的にどの部分を参考にしているのか。生成AIは、そこまで明示してくれます。
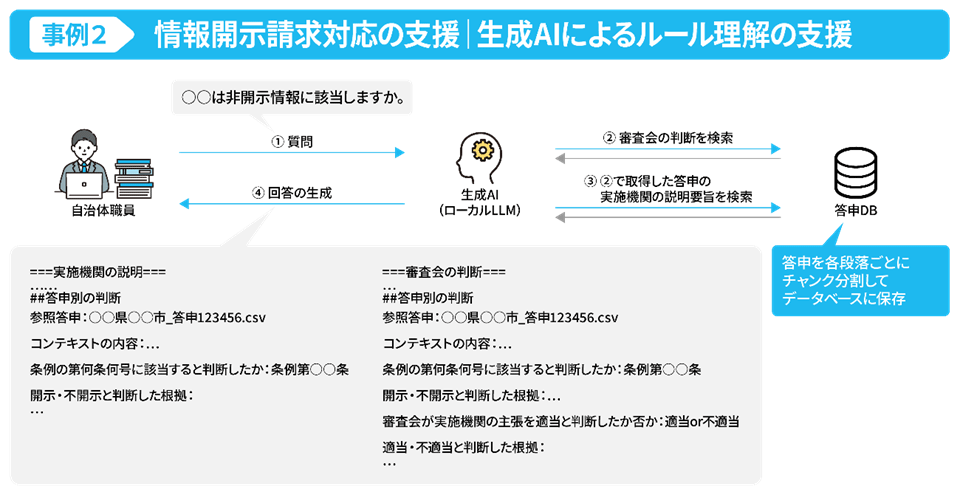
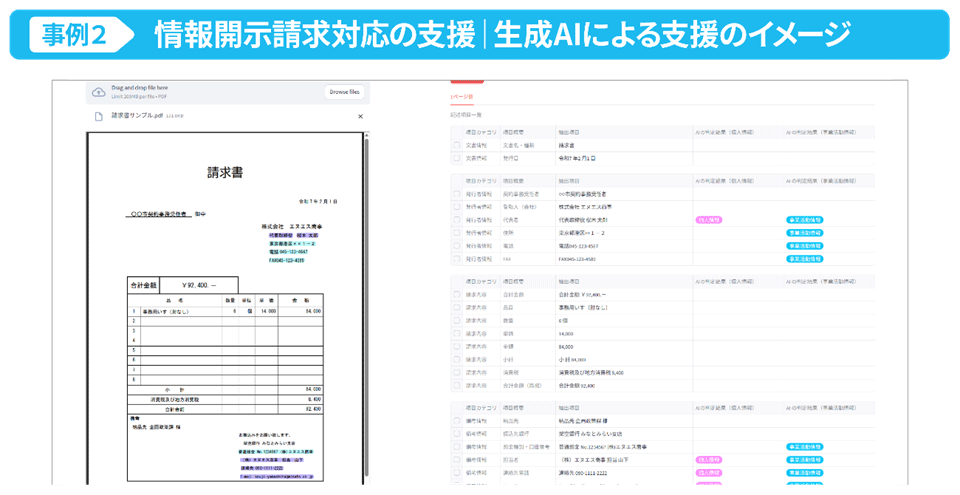
光野:ただし、生成AIはあくまで参考となる情報の提供業務を効率化するだけであり、最終的にどの箇所をマスキングするかは担当者が行っています。そういった意味では、先のメタデータの業務と同じく、現状ではAIエージェントにサポートしてもらっている、と言えるでしょうね。
――市民の個人的なデータも扱うため、セキュリティ面などで工夫されたのではありませんか?
大江:ご指摘のとおり、市民の個人情報を扱う際にはクローズドな環境で処理を行う必要がありました。そのため外部クラウドサービスを利用せず、ローカル環境で動作するLLMを活用し様々な工夫を凝らすことで、セキュリティ要件を満たしながら高度なデータ加工処理を実現することができました。一方、公開されている答申書を検索する際は、高性能なクラウドサービスの生成AIモデルを活用するなど、目的やデータの性質に応じて最適なモデル・技術を使い分けて、検証から導入まで取り組んでいます。
AIを活用したデータマネジメントの支援や代替が最終的な目標
――本日はありがとうございました。最後に、今後の展望などをお聞かせください。
大江:データ加工支援に関する取り組みならびに、実際に提供しているシステムは現時点では自治体さま向けとなっていますが、中央も含めた各都道府県の省庁や、近しい組織でも利用できると思っています。
光野:データカタログ整備の効率化においては、現在はデータスチュワードをAIエージェントが支援するという状況ですが、いずれはAIがデータスチュワードの役割を代替することで、さらなる効率化が実現できると考えています。
森:人からAIに各種業務が代替する流れはさらに進むと思います。そこで、AIがより効率的に稼働するデータやデータ基盤など、いわゆる「AI-Ready」な環境構築を目指していきたいですね。また、そのような環境の整備を踏まえた上で、データをどう整備すべきか、データカタログはどうあるべきかといった領域の研究を、より推し進めていきたいと考えています。
光野:今回ご紹介した、データスチュワード支援AIやルールに準じたデータ加工の支援にとどまらず、データマネジメントの幅広い領域において支援・代替を実現することで、お客さまのデータマネジメント推進にますます貢献していきたいと考えています。
