



個人情報の保護と活用を両立するプライバシー強化技術の中でも、特に元データの構造や統計的な特徴を保持して生成される「プライバシー保護合成データ」は、有用性・安全性を高いレベルで実現しうるものとして期待され、海外ではヘルスケア領域での活用事例が報告されている。一方で、合成データの法的な位置づけや利活用シーンが不明瞭であること、合成データ作成の標準的な技術が確立していないこと、などの課題が存在し、国内での合成データ普及の阻害要因となっている。本稿ではプライバシー保護合成データの概要と現状課題について調査した結果を報告する。
波多野 卓磨
日鉄ソリューションズ株式会社
技術本部 システム研究開発センター
インテリジェンス研究部 主務研究員
中田 良祐
日鉄ソリューションズ株式会社
技術本部 システム研究開発センター
インテリジェンス研究部 研究員
山下 信哉
小野薬品工業株式会社
デジタル戦略企画部
データ戦略室 主幹部員
データの活用を抜きにデジタルトランスフォーメーション(DX)は語れない。しかし、最も有用なデータの1つでありながら、その活用に大きな制限がかけられているものがある。それは「個人情報」だ。個人のプライバシーを保護する観点から、個人情報保護法、人を対象とする生命科学・医学系研究に関する倫理指針、ガイドライン等[1]により、個人情報の取り扱いに関する法的または事実上の細かなルールや制限が設けられている。もちろん、近年はグローバル化やAI・ビッグデータ自体への対応などを目的に個人情報保護法が改正[2]され、安全なデータ活用が進められるように変わってきてはいる。
しかし、データ活用の現場では、セキュリティ(データ管理)上の懸念などによって個人情報を活用しにくい状態が続いている場合が多い。個人情報が漏洩しないように、安全性を重視した厳格なデータ管理をしているためだ。最近は、改正個人情報保護法にて導入された匿名加工情報や仮名加工情報の制度に基づく、安全で有用なデータ活用の検討事例が出始めている[3]。しかし、こういった法制度の認知や活用の普及が十分に進んでいないという報告[4]もある。
より安全で有用性が高い「プライバシー保護合成データ」への関心が高まる
こうした現状に対し、セキュリティやプライバシー保護に対する懸念を低減しつつ、データ活用を一層進めていくための技術として、新たにプライバシー保護合成データ(以下、合成データ)に注目が集まりつつある。本稿における合成データとは、「実在するデータと同じ構造と類似した統計的特徴を持つ、プライバシー保護を目的として新しく生成した架空のデータ」を指す。実在するデータの特徴を参照し(参照する特徴は合成手法によって変わる。データ型や分布状況、データ項目間の相関など)、その特徴を再現するように人工的に生成したデータである。別途、プライバシー保護を目的としない合成データ(例:[5])や、生データに由来しない合成データ(例:[6])もあるが、これらは本稿の範囲外とする。
日本ではまだなじみが薄いが、海外では合成データに対する関心が高まっている。国連やOECD(経済協力開発機構)が2023年に発行したプライバシー強化技術(Privacy Enhancing Technologies:PETs)に関するレポート[7][8]では、PETsの1つとして合成データが紹介されている。また、G7広島サミット(2023年5月開催)の関係閣僚会合では、特に合成データの活用に注目した推進計画が発表された[9]。
日鉄ソリューションズと小野薬品工業は、安全性と有用性を両立したデータ活用の実現に向けたプライバシー保護技術の調査を共同で進めており、直近は特に合成データに注目して調査を進めている。本稿は、2023年4月から2023年11月までに実施した調査結果を含むものであり、合成データの普及に向けて、その特徴と現状の課題について認知を高めることを目的として作成した。
合成データは、実在するデータと「同じ構造と統計的特徴」を持つ
図1を見てもらいたい。図の左側が元の個人情報で右側が合成データだ。合成データは、元の個人情報の列ごとのデータ型や値域等が類似しており、見た目に大きな違いが無いように作られている。また、適切な合成手法を用いることで、列ごとの値の分布や、2列の相関などの簡易的な統計的性質を類似させることができる。合成データは、AI(人工知能)モデルや統計モデルなどの、元の個人情報の構造や統計的特徴を抽出する仕組みを利用して生成する。そのため、元の個人情報と合成データの各行には直接的な関連性はなく、合成データから元データを復元することは、多くの場合難しい。
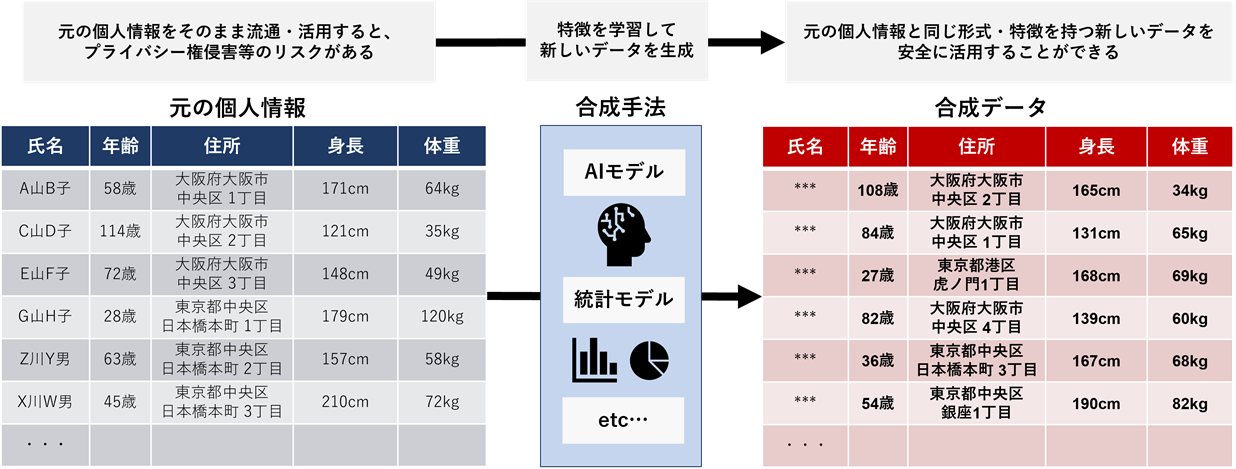
図1のケースでは、例えば元データの「身長や体重の分布状況」や「身長と体重の相関」などを学習・分析してAIモデルや統計モデルを作成している。そのモデルから、同じ分布や相関を持つデータを合成している。
元の個人情報と合成データの構造や統計的特徴が類似していれば、それらを用いたデータ分析の結果に大きな差は現れない。合成データの活用は、元の個人情報の活用を一定程度代替しうるものである。
匿名加工情報、その他既存のデータ種別との比較
日本では、法令が定める基準に従って個人が特定できないように個人情報を加工した「匿名加工情報」や、他の情報と照合しない限り個人が特定できないように個人情報を加工した「仮名加工情報」の活用が可能になっている。個人情報保護法における匿名加工情報は、法令で定められた基準・手続きを満たすことで、本人同意を取得することなく、利用目的以外での活用や第三者への提供が可能になる。
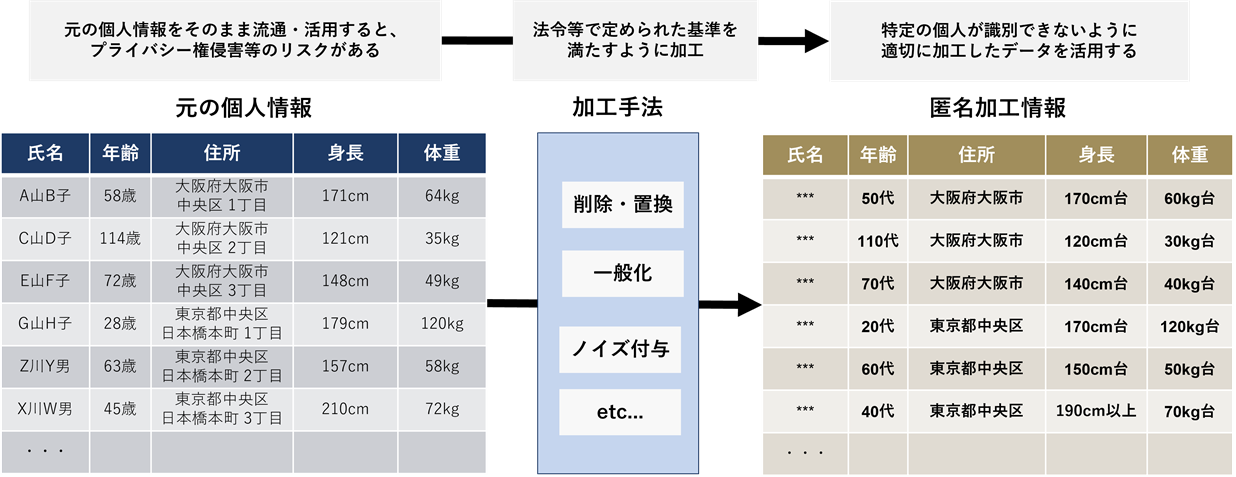
匿名加工情報は、その加工過程で生データの特徴(分布や相関)が変化してしまう可能性がある点に注意が必要だ。例えば、匿名加工情報の作成時には、個人の特定を防ぐために、特定の値を削除するか、一般化した値に置き換えなければならない場合がある。このような措置によってデータの特徴が大きく変化してしまうと、データの有用性が損なわれてしまう。
匿名加工情報のほかにも、「仮名加工情報」「統計情報[10]」がある。次の図3は、それぞれのデータ種別と合成データについて、安全性・有用性の観点で比較した概念図である。
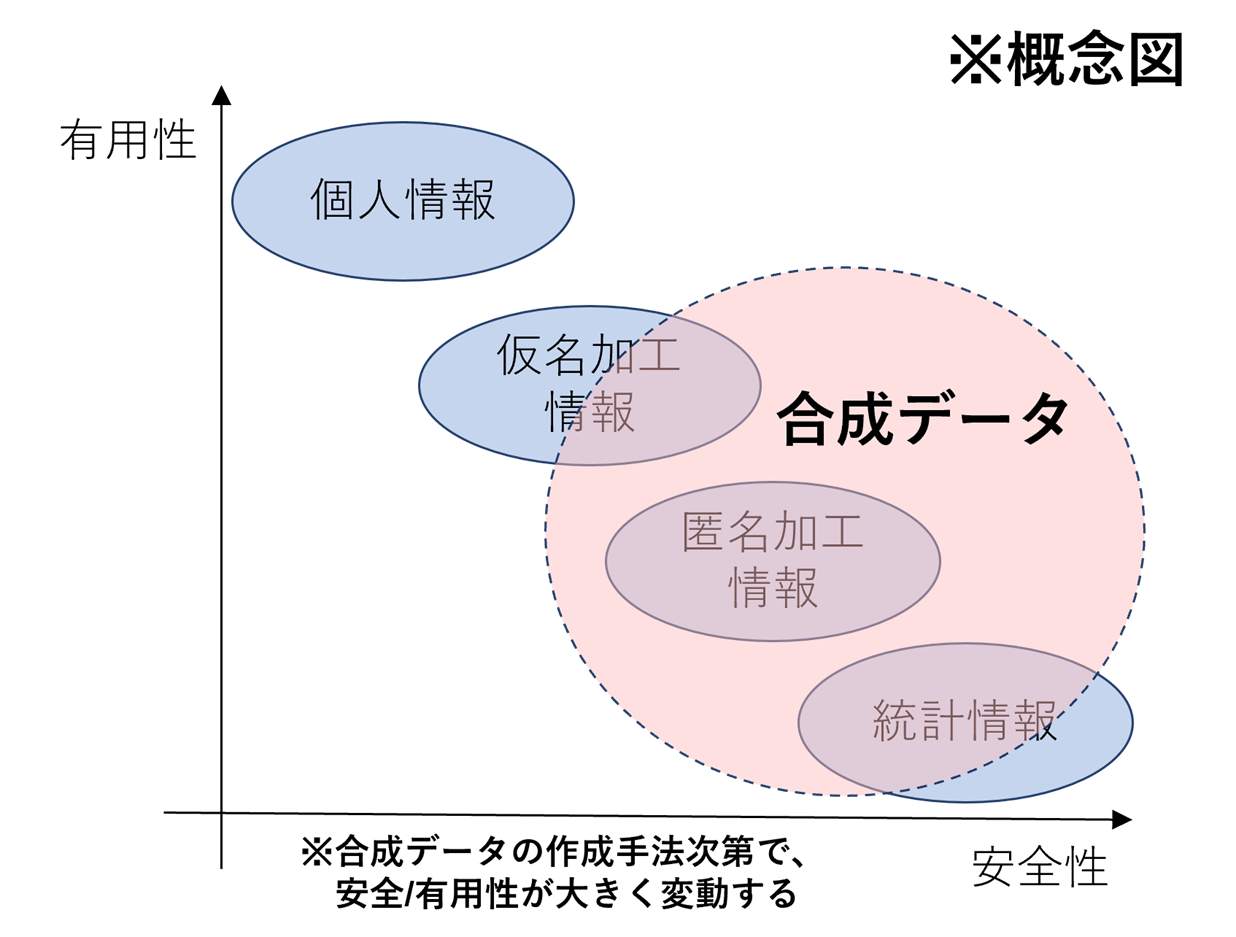
プライバシー保護の面で、匿名加工情報は個人を特定できないように加工されるものの、どのレベルまで加工すれば匿名加工情報としての要件を満たすことになるのか判断が難しい面があり、あいまいさが残る。元の個人情報や仮名加工情報は安全性の面で、統計情報は有用性の面でそれぞれ課題がある。これに対し、適切に作成された合成データは、元の個人情報との関連が断ち切られた新しい「架空のデータ」であるという点で匿名加工情報よりも高い安全性を持ち[11]、個人情報や仮名加工情報の有用性を高いレベルで再現できる可能性がある、と言えるだろう。ただし、安全・有用な合成データの作成方法はまだ定まっていないため[12]、生成・評価手法の検討が不足していると、プライバシーの侵害やデータ活用の阻害が発生しうる点には注意が必要である。
海外では、新型コロナウイルスの研究に用いられる事例も
ヘルスケア領域における合成データの活用は、海外では進行している。図4は、米ワシントン大学でのヘルスケア領域における合成データ活用事例である。
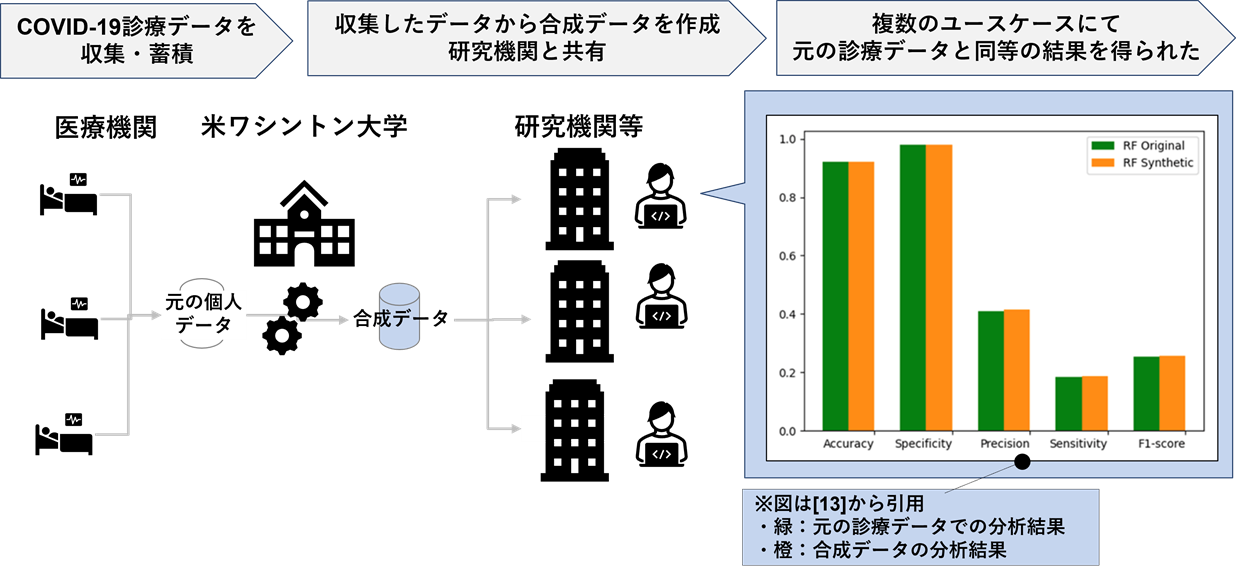
新型コロナウイルスのパンデミックを一刻も早く収束させるためには、研究者に広くデータを利用してもらう必要がある。一方、取得した診療データの安全管理も必要となり、配布・公開は難しい。そこでワシントン大学は、合成データを作成して外部と共有している。作成された合成データの品質については、ワシントン大学とイスラエル企業MDClone社の論文[13]にて、複数のユースケース(陽性患者の主要な特徴の探索や、入院リスクの予測モデル構築、流行曲線の予測など)を通して確認されている。論文中では、合成前後で比較すると、一部の例外はあるが全体的にはほぼ同じ結果が得られた、と報告されている。本事例は、合成データを元の個人情報と同様に扱える可能性を示唆している、と言えるだろう。
合成データを用いたデータ管理・活用の効率化
また英国では、研究計画立案のためのフィージビリティ検証目的で合成データが用いられる事例もある。
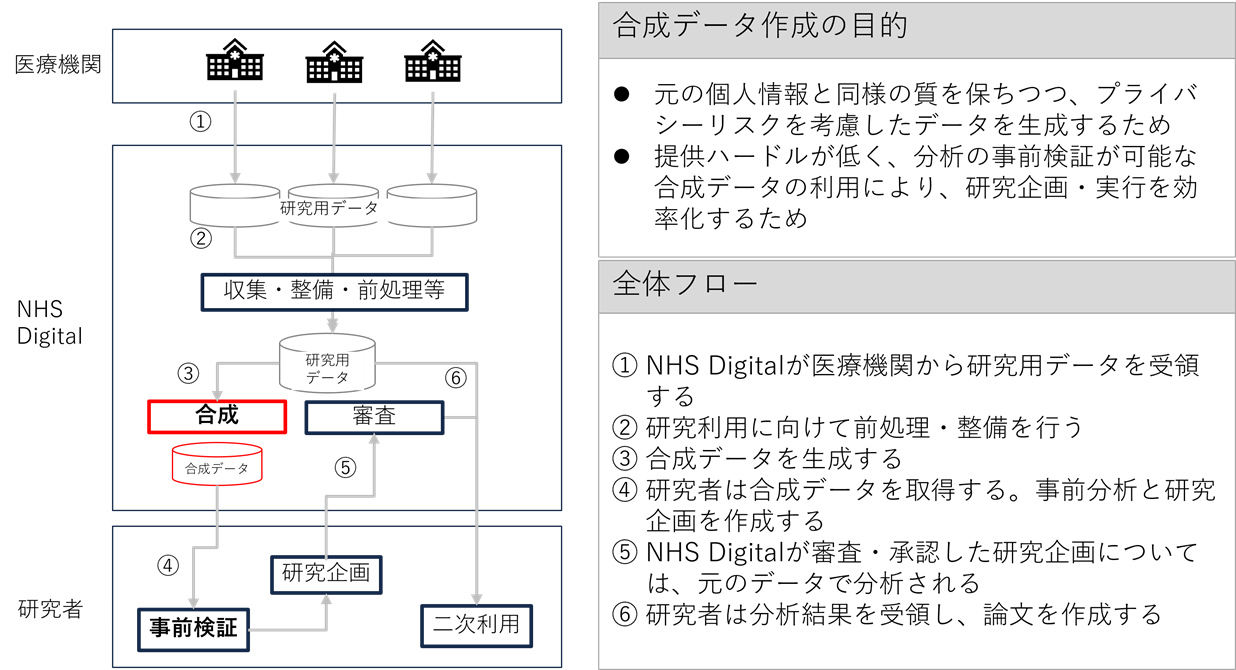
英国のNHS Digital[14]は、取得・蓄積したがん臨床データを基に、データ形式や統計量を一定程度保持した合成データを作成・配布している。当該データには、百万人以上の合成患者の、肺がん・乳がん等の検査データが含まれている[15]。研究者は、申請・審査が不要ですぐに利用できる合成データを用いて、研究企画の検討や分析用プログラムを作成することができる。合成データにて検証した研究企画とプログラムは、NHSに提出して審査・承認されれば、NHSにて生の個人データに適用されて、分析結果が研究者に提供される。研究者は、こうして得られた分析結果を論文作成に用いることができる。
このような合成データの活用方法は、機微データの活用企画の速度や、データ管理の効率に大きなインパクトを与えるだろう。
合成データは法制度上のグレーゾーンに位置する?
合成データの活用には大きなメリットがある半面、現状の法制度において合成データはグレーゾーンに位置している、と言える。この点について宮内・水町IT法律事務所の水町 雅子弁護士と議論した際、同弁護士は次のようにコメントした。
現行の個人情報保護法下では「個人情報」「仮名加工情報」「匿名加工情報」「統計情報」等の分類が存在するが、合成データがそのどれにあたるか、あるいは別のものとされるのかは、明確になっていない。
法的リスクについて不明確な現状では、合成データを活用しづらい。一方で、匿名加工情報の基準を満たすように合成データを生成できる場合も考えられるし、また特定の個人との対応関係が完全に排斥された情報は個人情報には該当せず[16]、統計モデルそのものも個人情報に該当しないため[17]、適正な加工を担保した上で、これらとの類似性を検討するという方向も成り立ち得ないものではない。
また、冒頭に述べたようにG7関係閣僚会合による計画が示されているものの、国内の合成データに関する法解釈・法改正などの方向性は、2023年11月時点では見えていない。適切な合成データの生成方法と、生成された合成データの位置づけに関する法的解釈について、今後詳細化・具体化していく必要がある。
安全な合成データを生成する方法は?「データ合成技術評価委員会」の取り組み
合成データの生成には様々な手法が提案[18]されており、その評価手法は統一されていない。例えば合成データの安全性については、メンバシップ推定という攻撃により、あるデータが元データに含まれることが漏洩しうると指摘されており[19]、その対策のための評価が必要になる。
こういった技術的な課題の解決に向けた取り組みが日本で開始されている。2023年4月に、情報処理学会コンピュータセキュリティ研究会の分科会であるPWS組織委員会は「データ合成技術評価委員会」を立ち上げ、健全な合成データの利活用促進を目的とした活動を開始した[12]。当該委員会は、匿名性の低い合成データの利用によるプライバシー漏洩のリスクや、基準・手法が不明確であることによる技術適用の阻害、などの課題を想定している。これらの課題解決に向けて、プライバシー保護の有識者・実務者が、データ合成技術の評価や匿名性基準の検討をしている。この取り組みにより、合成データを活用する際の技術的なベストプラクティスが普及することで、合成データ活用の拡大が期待される。
合成データ普及を目指したユースケース整備
合成データ活用の普及に向けては、業界ごとの具体的なユースケースの整備・共有も重要である。日鉄ソリューションズと小野薬品工業は、安全性と有用性を両立したデータ活用に向けた技術調査の一環として合成データに注目しており、製薬企業でのユースケースを検討している。
製薬企業は、個人情報を含んだヘルスケアデータを多く保有している。一方で、保有しているデータは、取り扱いが厳格な「要配慮個人情報」を含んでいるので、データの社内流通は非常に慎重に行われている。そのため製薬企業は、個人情報を含んだヘルスケアデータを安全に社内流通させ、安心して二次利用できる技術として「合成データ」に注目している。近年「データ利活用基盤」を構築し、積極的にデータ活用している製薬企業も多くなってきた。法的・技術的な課題が解決すれば、米ワシントン大学の事例を参考に、適切な手法で作成した合成データを「データ利活用基盤」に投入し、部門横断で活用する環境を提供することが可能になる。これにより、データ活用アイデアの発生を促し、データ活用による価値創出の機会を提供できると考えている。
今後は、合成データ活用の普及に向けて、弁護士や技術者と連携を深め、技術・法律・実用面での課題解決を目指して連携を深めていきたい。
おわりに
本稿作成のための調査・執筆にあたり、多くの方々にご支援いただきました。
貴重なご助言を賜りました下記の皆様に、深く感謝の意を表示します。
- 小野薬品工業株式会社開発本部 小谷 基様、渡辺 寿恵様
- 宮内・水町IT法律事務所 水町 雅子様
その他本文記載の会社名及び製品名は、それぞれ各社の商標又は登録商標です。
参考文献リスト(URLは2023年11月16日時点のもの)
- [1] https://www.ppc.go.jp/personalinfo/legal/
- [2] https://www.ppc.go.jp/files/pdf/revised_APPI_leaflet2022.pdf
- [3] https://dcross.impress.co.jp/docs/talk/003384-3.html
- [4] https://www.datascientist.or.jp/common/docs/CMH_SurveyResults_20190712.pdf
- [5] https://arxiv.org/abs/1802.05891
- [6] https://github.com/faker-ruby/faker
- [7] https://unstats.un.org/bigdata/task-teams/privacy/guide/2023_UN PET Guide.pdf
- [8] https://www.oecd-ilibrary.org/docserver/bf121be4-en.pdf
- [9] https://www.ppc.go.jp/files/pdf/G7roundtable_202306_actionplan_jp.pdf
- [10] https://www.ppc.go.jp/personalinfo/faq/APPI_QA/#q1-7
- [11] https://jglobal.jst.go.jp/detail?JGLOBAL_ID=202202251039781797
- [12] https://www.iwsec.org/pws/ppsd/index.html
- [13] https://www.jmir.org/2021/10/e30697/PDF
- [14] https://digital.nhs.uk/ndrs/data/data-outputs/simulacrum
- [15] https://simulacrum.healthdatainsight.org.uk/available-data/
- [16] https://www.ppc.go.jp/personalinfo/legal/guidelines_anonymous/#a3-1-1
- [17] https://www.ppc.go.jp/all_faq_index/faq1-q1-8/
- [18] https://www.sciencedirect.com/science/article/abs/pii/S0925231222004349
- [19] https://arxiv.org/abs/2007.12087
